Laying the foundations: Lists in Medium’s feature store, Part 1
Explore the foundations of the new list feature type in Medium’s feature store.
tl;dr
This is the first installment of our series on the new list feature type in Medium’s feature store. Central to Medium’s recommendations system, the feature store handles the high-volume data used by machine learning models. The limitations of the existing relational features prompted the development of the new list feature type, which is designed to handle cross-entity relations in an efficient and scalable way.
See also Part 2: ScyllaDB implementation.
What is the feature store?
The feature store is a key component of Medium’s recommendation system. It functions as a repository to store features that the machine learning (ML) models use to power recommendations. It can be thought of as a database with a specialized API designed to handle the high-volume, high-throughput access patterns these ML models require.
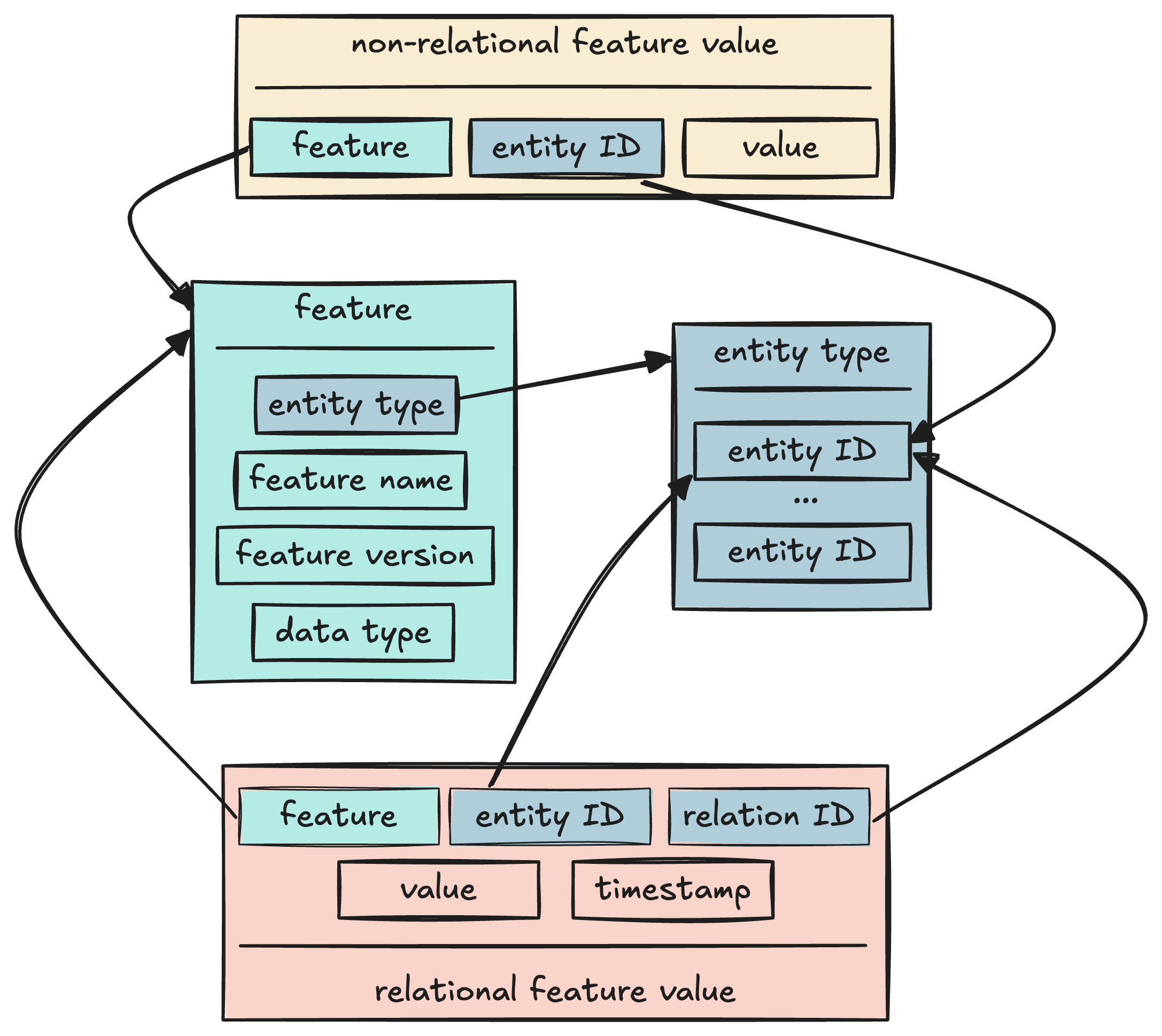
A feature represents a property of an entity in the feature store. A feature is defined by:
- The entity type the feature is associated with. For instance:
user,story. - Its name. For instance:
is_memberfor theuserentity type,authorfor thestoryentity type. - Its version (optional). We use feature versions to store feature values that were generated at the same time and that should be queried together.
- The data type of its values. For instance: integer, string, float vector.
A feature value is the value of a feature for a given entity ID. For instance, the value of the title feature for the story entity with ID badcaffe could be the “The Surprising Benefits of Reading Every Self-Help Book Backwards” string.
Medium’s feature store also supports relational features. A relational feature can have multiple values for a given entity ID; each of these values has an associated relation ID, which is the ID of the related entity, and a timestamp. For instance, the user_has_read relational feature for the story entity type relates with the user entity type and stores boolean values indicating whether and when a given user has already read a given story.
These concepts and their relationships are illustrated in the following schema:
As we’ll describe below, the limitations of relational features were the primary driver for introducing the new list feature type.
The list feature type
Medium’s recommendations team had been constrained for some time by the technical limitations of relational features. Because of the data model used to store relational feature values in the database, each fetch request for a relational feature generates one database query that retrieves the entity IDs matching the request constraints, followed by one additional database query for each entity ID returned by the first query to retrieve the feature values for these entity IDs; obviously, these multiple queries are inefficient. The data model also makes it hard to rely on primary keys and/or indices to optimize these queries, which significantly adds to the inefficiency of relational features. In addition to that, the API exposed by the feature store to manipulate relational features is clunky and outdated.
The team thus set out to find a better way to handle cross-entity relations in the feature store. We quickly rejected the option of refactoring the existing implementation of relational features. The feature store currently handles significant volumes of relational feature values; refactoring its implementation in-place would have been costly, lengthy, and risky. We instead agreed that it would be more valuable to add a new feature type with a streamlined API and an efficient implementation, then to progressively migrate existing relational features to this new feature type.
That’s where list features came into play. A list feature has the following characteristics:
- Like other features in the feature store, a list feature is associated with an entity type and has a name and an optional version.
- A list is the value of a list feature for a given entity ID, consisting of a collection of items.
- Each item in a list stores a value and a timestamp.
- A list feature has a mandatory associated time-to-live (TTL) value. Items in a list that are older (based on their timestamp) than the TTL of their list feature are considered expired and will be expunged at some point.
- The data type for item values are not constrained. Two distinct item values in the same list can have different data types (integer, string, float vector, etc).
The following schema illustrates the new list feature type:
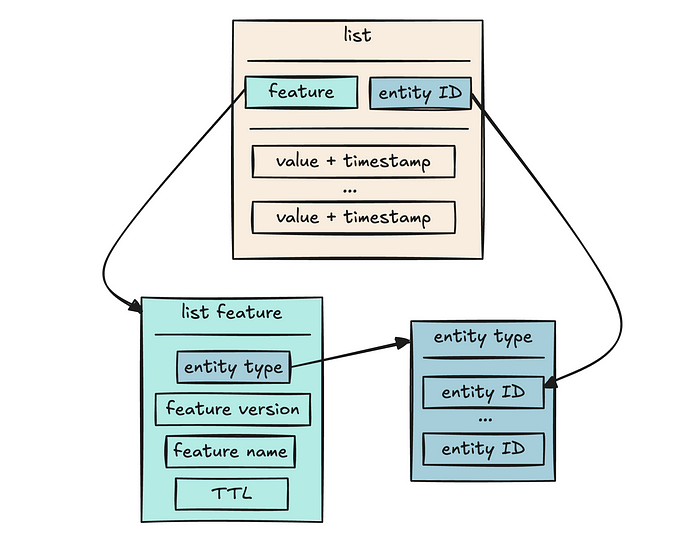
Let’s consider a reading_history list feature on the user entity type as an example. This list feature has a TTL of 6 months. The items of this list feature for the johndoe user ID records the IDs of the stories that this user has read in the last 6 months, along with the timestamps of when these reads occurred. The reads that were recorded more than 6 months ago are automatically deleted from the list; this helps control the storage space used by list items, so that we don’t end up storing (and paying for!) multiple years of data that we don’t need.
Operations on list features
After having defined the characteristics of list features, we’ve listed the operations to be supported on list features, along with the expected call rate of each of these operations. This information will be a key input when it will come to defining an efficient data model for list features (see the next installments in this series).
The operations on list features are as follows:
Create List Feature — This creates a new list feature for a given entity type and with a given name and TTL. This operation is rarely used, with an expected rate of less than 1 call per day.
Delete List Feature — This deletes an existing list feature, specified by its entity type and name. All the versions associated with the list feature, if any, and all the items associated with the list feature are also deleted. This operation is also rarely used, with an expected rate of less than 1 call per day.
Add List Feature Version — This adds a new version to an existing list feature. Versions are usually created daily, so this operation has an expected rate of a few calls per day.
Delete List Feature Version — This deletes an existing version of a list feature, along with all the items associated with this version. Versions are usually deleted a few days after they’ve been created, so this operation has an expected rate of a few calls per day.
Get List Items — This retrieves the items of the list identified by its entity type, feature name, optional feature version, and entity ID. Items are returned in the reverse chronological order of their timestamps. Callers also specify a maximum age for items and a maximum number of items to retrieve. Our estimates showed that we expect callers to retrieve list data at rates comprised between 100k to 1 million items per second, and possibly more in the future. It is thus essential that the implementation of this operation is able to (a) support significant amounts of requests with low latencies and (b) scale to accommodate future traffic increases.
Add List Items — This adds items (values and timestamps) to the list identified by its entity type, feature name, optional feature version, and entity ID. Estimates showed that we expect to be writing between 10k to 100k items per second, and possibly more in the future. As with the Get List Items operation, it is essential that the Add List Items implementations is efficient and able to scale in the future.
Remove List Items with Value — This removes all the items with a given value from the list identified by its entity type, feature name, optional feature version, and entity ID. This operation has an expected rate of between 1k to 10k calls per second.
Remove All List Items — This removes all the items from the list identified by its entity type, feature name, optional feature version, and entity ID. The expected call rate of this operation is unknown.
This is summarized in the table below:

What’s next?
Let’s quickly review the key points we’ve covered so far:
- The feature store powers Medium’s recommendations system by storing and managing features used by machine learning models.
- A feature in the store is defined by its entity type, name, optional version, and data type.
- Relational features handle cross-entity relations. They are limited by inefficiencies in their data model and outdated API.
- We’re introducing a new list feature type to address the limitations of relational features.
- Lists will store collections of items with values and timestamps and have a mandatory time-to-live (TTL) to control storage size.
- The key operations on list features that require high efficiency and scalability are retrieving items from a list and adding items to a list.
The next installments in this series will cover how we implemented this new list feature type. One of our goals with lists was to use them as an experiment to compare ScyllaDB (see part 2) and DynamoDB in terms of efficiency and costs using production data. Stay tuned to learn more!

