Mapping Medium’s Tags
Machine learning brings Medium’s tags to life
This was originally published Jan 18, 2018 on Hatch, Medium’s internal instance, to explain a hack week project to the company.
When you publish a post on Medium, you’re prompted to add labels to your post that describe what your post is about. These tags are mostly free-form. Authors can write whatever they think describes their post.

As far as data goes, these tags are a gold mine. Authors are labelling their posts with a succinct word or phrase that other people understand. We can (and have) used these tags to inform our algorithms for showing content and organizing it.
However, there are big issues with tags that limit their usefulness. One of the issues is that tags are scattered. At this point, authors have defined over 1 million unique tags. Many tags are essentially duplicates of other tags, or are so close that they have the same audience. Here are some examples:
- Global Warming = Climate Change
- Hillary Clinton = Hilary Clinton (common misspelling)
- Poetry = Poem = Poems = Poetry on Medium
- Startup = Entrepreneurship = Startup Lessons = Founder Stories
To computers, each tag is just a string of text and by default they don’t have meaning or relatedness. This makes it hard for us to wield them cohesively in algorithmic battles.

Tags as multi-dimensional characters
Instead of each tag just being represented by a string, what if we could represent it by its qualities and how it relates to other tags? When we talk about people, we don’t compare them by their names, rather we describe and compare them by the many qualities they have. People are “multidimensional” to us. What if tags were too?
We’re going to take the word “multidimensional” literally, and represent each tag by a vector of numbers in a multi-dimensional vector space.
First of all, what is a vector? For the sake of this project’s Python code, a vector is just a fixed-length array of numbers. However, you can interpret this list of numbers in different ways. You could interpret it as a point in space (e.g. (5,3) is the point that is offset 5 along the x-axis and 3 along the y-axis in 2-dimensional space). However, sometimes it’s more useful to interpret it as a vector with direction and magnitude, the ones you might remember from Physics class. It’s confusing. I recommend this short video explanation.
If we could represent tags with vectors then we could compare them by distance or plot them to visualize the clusters they form. Spoiler: we’re going to do just that.
Training the tag vectors
But how do we find the meaning of these thousands of tags in a way that can represented by vectors of numbers? We do this by training a machine learning model using our tag data.
The training data I used was the tags of 500,000 “reliable” public English Medium posts. I pretended each post’s tag list was a “sentence” (where each tag is a “word”), and fed those into a training algorithm which usually takes real sentences and learns vector representations of words. I used gensim’s word2vec implementation for this, and I specified that these vectors should have 100 dimensions.
I won’t go into details about how the training algorithm works, but essentially it figures out a tag’s vector values by looking at the tags that are used along with it on posts. You can read more about the algorithm here.

Algorithms such as word2vec are said to “embed” entities (like tags or words) in a multi-dimensional vector space, and as such, these kinds of vectors are also known as “embeddings”. If you’re googling for more information about all this, you’ll want to search for “embeddings”.
Examining the vectors
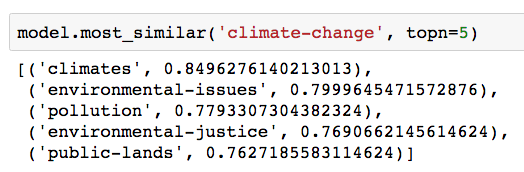
After a few minutes of training, we get the vectors for every tag at our disposal. Let’s check one out. Here’s the vector for “Climate Change”:

Great. Don’t worry, you shouldn’t understand what these numbers mean. I couldn’t even tell you myself. Unfortunately, it’s not even as simple as saying “the Xth dimension represents Y quality and the value is how much the tag expresses that quality”. Rather, the dimensions work in concert to represent information about the tags.
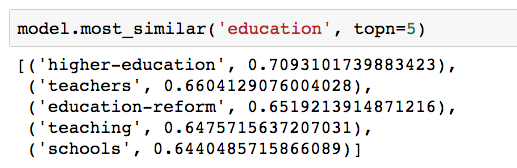
It’s easier to see what’s going on by comparing vectors. One thing we can do is find tag vectors that are close to each other. Here, we interpret them as vectors with direction and magnitude in order to compute the cosine similarity between them:

Combining Vectors
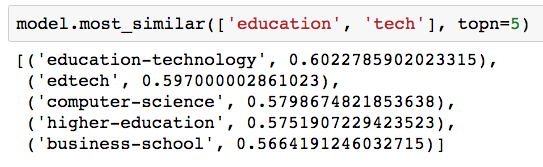
We can also do arithmetic on our vectors to jump around the vector space. Here we average the “Tech” vector with “Education” to land in the vicinity of EdTech tags:
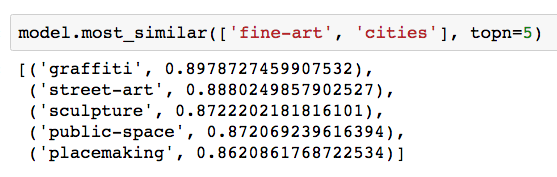
Now we can try “Fine Art” + “Cities” to get “Graffiti”:
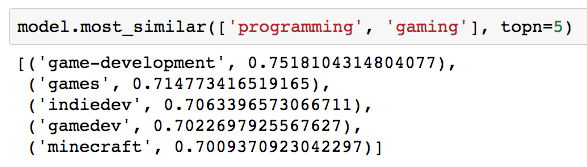
“Programming” + “Gaming” is “Game Development”:
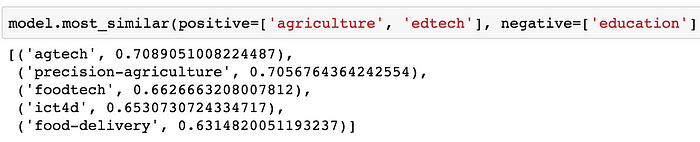
We can also solve analogies, like this one, which is essentially "Education" is to "EdTech" as "Agriculture" is to _:
The fact that we can perform this basic arithmetic and reliably get these results indicates that we’ve learned some “linear regularities” of the tags. People have found similar, but more linguistic, regularities in word embeddings obtained by training word2vec on real words and language.
Visualizing the vectors
We can also plot the tag vectors. Now, we switch to interpreting them as points in space. However, since we can’t visualize points in 100-dimensional space, we’ll have to reduce them to two dimensions.
To do so, we don’t just take the first two dimensions of the vectors and call it a day. Rather, we try to preserve some information from all of the dimensions, and keep points which are close in the 100-dimensional space close in the 2d space. There are a myriad of ways to do this “dimensionality reduction”. One that is particularly good for visualization is t-SNE.
The plot of this 2d tag space is large, even if we’ve limited it to only tags which have more frequent usage, so we’ll take a closer look at some smaller regions of it.
The Medium Tag Universe:

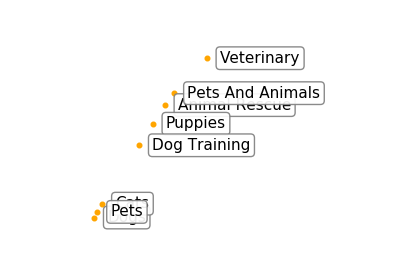
The “Pets” Solar System:
The “Music” Spiral Galaxy with “Podcast” Arm:
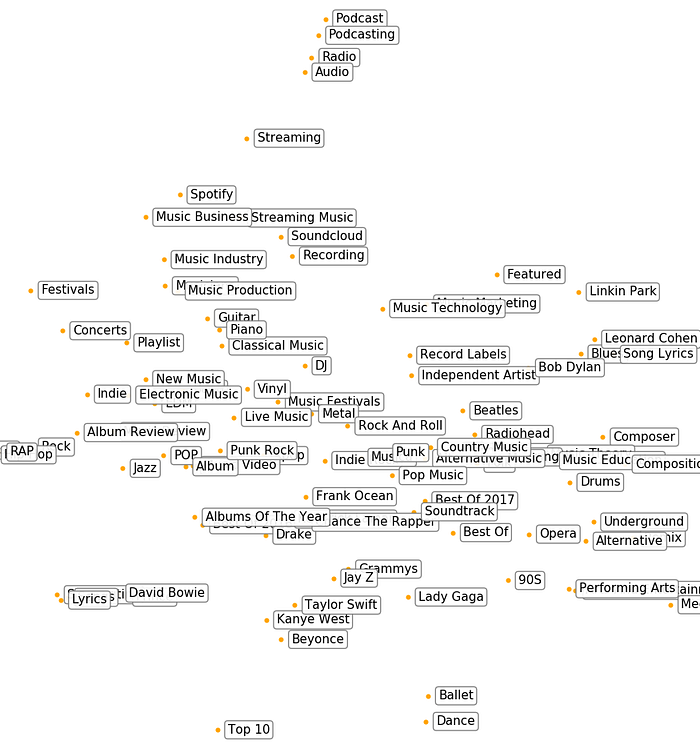
The “Storytelling” Galaxy Group:

The “Data” Galaxy:

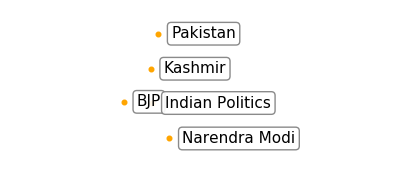
The “Indian Politics” Solar System:
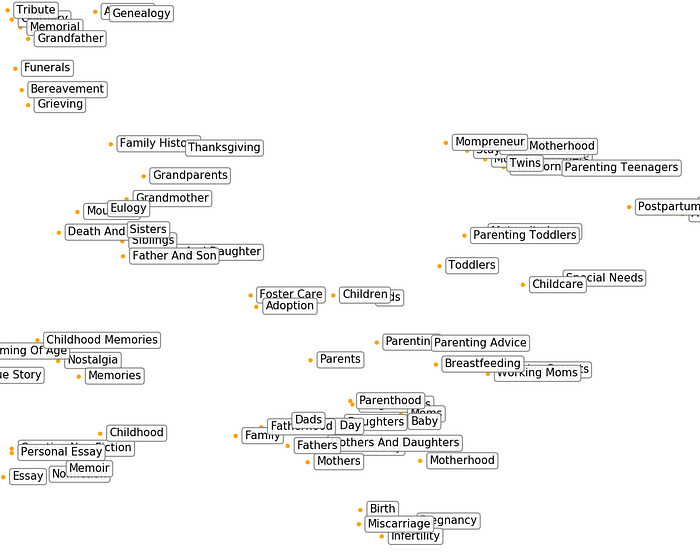
The “Family” Nebula:
The “Gaming” Binary Galaxy:

The “US Places” Galaxy:

Places are invariably clustered together, and often grouped by geography. Some places are located within other topical clusters. Virginia and Alabama are in the US Politics cluster. European and Asian countries are located in the Travel cluster. African countries are with non-profit and development tags.
“Seasons” intergalactic dust:


You might be wondering where “Spring” is. On Medium, more people are talking about software frameworks named Spring, than the season, so it’s located near Java tags in the computer programming cluster.
The “Storytelling” Galaxy in the Portuguese Universe:

Previously, we trained a tag embedding model using English posts only. If we train one using Portuguese posts, then we can relate Portuguese tags to each other.
Use Cases
Other than being really cool, there are several possible downstream uses for these tag vectors now that we have them.
Synonymous tags
There are many sets of tags on Medium that mean the same thing (e.g. “Science Fiction” and “SciFi”). Tags which mean the same thing are usually very close in the vector space. This could help us identify duplicate tags and normalize them.
Other predictions
Aside from helping us organize the tag space itself, these tag vectors could be used to help solve other prediction problems with machine learning. Machine learning algorithms take vectors as input features. We could include tag vectors in any place where knowing the post’s tags might help with a prediction.
Being able to use these “dense” expressive vectors instead of the alternative for tags — sparse one-hot-encoded vectors — should improve the algorithms’ ability to predict. The beginning of TensorFlow’s word2vec doc describes why these vectors are better.
Issues and Improvements
The tag representations we’ve learned aren’t perfect. Here are some things we’d need to consider for future usage of tag vectors at Medium.
Ambiguous tags
There’s an issue that we’ve already seen with the “Spring” tag: ambiguity. “Spring” has at least two meanings on Medium. Many people use the tag for poetry about the season, but others use it for posts about the Java programming framework. We need to automatically detect that there are two distinct representations to learn: “Spring (season)” and “Spring (programming)”. This problem is called “word-sense disambiguation”. Luckily, it’s an area of active research.
Bias
People have discovered negative stereotype biases in word embeddings (e.g. “boss” relates more strongly to “he” than “she”). I’ve been thinking about what this would mean for our tags. Obviously, these tag embeddings are completely at the whim of how people choose to use tags on Medium. We’re bound to have some undesirable algorithmic bias.
Since countries represent groups of people, I thought it might be undesirable to associate countries with topics in some circumstances. African countries are quite close to charity tags. Puerto Rico = hurricanes, as far as tags are concerned. For any downstream use case, we’d have to consider this. De-biasing embeddings is an area of active research as well.
Associating tags across languages
If we find some tags that we know to be counterparts in another language, then we can train a cross-lingual model that embeds the tags from both languages in a shared vector space, so they could be directly compared.
Alternate training algorithms
We’re learning the “meaning” of these tags based on the tags that are chosen alongside it by authors, using word2vec. This was chosen because it was easiest to implement end-to-end. It’s possible that learning the vectors using other information would produce more effective vectors for us. For example, we could learn them using reading behavior instead of tag context. It’s also possible that it would find very similar relationships.
Resources
If you’re interested in learning more about embeddings and the algorithms used here, I’d recommend these resources:
- Original word2vec paper. The algorithm used to train word vectors, which we repurposed to train tag vectors.
- Linguistic Regularities in Continuous Space Word Representations (pdf). All about the neat analogies and arithmetic you can do with word vectors.
- Original t-SNE paper (pdf). The dimensionality reduction technique used to take our 100-dimensional vectors down to a 2d visualization.
- Deep Learning, NLP, and Representations. If you already know a bit about neural networks and how they work, this post has a great explanation about how embeddings (including word vectors) are trained as a side effect of solving another task.
- Word embeddings in 2017: Trends and future directions