Rex: Medium’s Go Recommendations Microservice
Editor’s note: This blog post was originally written in early 2019. It gives a great overview of why we built Rex and how it initially worked, but a lot has changed since then. Look for future stories on how Rex has evolved over time.
At Medium, we’re focused on delivering the best stories to the users most interested in them. We want to provide as many high-quality stories for our users as possible and have them ready as soon as they open Medium, whether on the site, in the app, or in emails. You’ll often see them in the form of a list of stories (which we call a ranked feed). However they’re using Medium, users can scroll through a ranked feed of stories, searching for the best story that fits them at that moment.
In March 2018, the recommendations team at Medium began to explore how we could improve our ranked feeds. We knew we wanted a feed that could quickly deliver as many personalized, high-quality stories as possible for a given user. However, as we delved into the parts of our code powering our ranked feed, we realized that our feed was neither quick to render nor sourcing as many stories as we felt it should. As an example, our homepage feed could take up to seconds to create, and we could not rank as many candidates as we’d like: only around 150 stories. There are hundreds of thousands of incredible stories on our platform — we want to be able to source recommend as many candidates as possible whenever a user goes to Medium.
In order to build a recommender system that could source many stories and do so quickly, we decided to go back to the drawing board and build an entirely new service from scratch.
Before delving into how we built it, we should take a look at the problems with the old one that were holding us back.
One issue was technical debt: As we first made small tuneups to our recommendations system back in March ’18, we found that testing and verifying each change was far more time-consuming than we’d like. Bugs would pop up that were difficult to catch in tests and reproduce. It was clear that if we wanted to move more quickly and test new recommendation strategies, we would at least need a major refactor of the code that existed.
However, the biggest issue was language choice. Much of Medium runs within a Node.js monolith, including the code that used to power story recommendations. Node, despite its many strengths, it wasn’t the best tool for this particular task.

Node is single-threaded (at least, it is how we use it at Medium). There are no concurrently running operations: All requests are scheduled via a system called the event loop. When a request makes an I/O call, it goes to the back of the event loop and yields use of the CPU to the next request in line.
This is great when the computation done per request is pretty simple. Unlike in a synchronous I/O world—where a request might still hold the CPU while waiting for the I/O operation to complete—the CPU is never idle, and no request is hogging the CPU for too long a time. When we have requests that don’t demand too much uninterrupted time of the CPU, we see Node at its finest. The top example in the diagram above is such an example.
This is not the case when fetching all the data to put a ranked feed together. Sourcing the stories we want to rank, getting the data to rank many stories, using different ranking services to order those stories effectively: This is just some of the heavy lifting happening for each request to form a ranked feed. Each of these subtasks makes many I/O calls themselves. Hence we’re often giving up the CPU to other requests, and when we have the CPU, we’re holding it for a long time. Making matters worse, when we give up control of the main thread, other requests could be taking the CPU a while as well, causing our request to build a feed to get slower and slower.
In short, we’re putting heavyweight operations in a runtime environment that’s optimized for much more quick and simple tasks. If we wanted to build a more performant recommendations system, Node probably wasn’t the answer.
With all this in mind, the recommendations team at Medium decided we had to make a change. Thus was born a new service at Medium: the recommendations microservice Rex.
Before delving into how Rex works, it’s useful to clarify two things:
- What we mean by microservice.
- Why we chose Go as the language for Rex.
With respect to the first, I highly recommend reading this story by a former Median, Xiao Ma, for thoughts on microservices, but as a TL;DR: We want our recommender system to be deployable separate from the rest of the codebase. Developing in a new microservice makes the test/ship/deploy process far quicker.
As for the second, we considered a few languages, but we landed on Go for the following reasons:
- More efficient use of the CPU. While Node is single-threaded, Go is much better suited for the combination of I/O and CPU-intensive operations required to build a ranked feed. Splitting our work onto separate Goroutines means we can avoid the issue of the CPU getting hogged by one single request and other requests getting starved.
- Opinionated. Go makes it pretty hard to write “bad” code. A typed language that is also highly opinionated in terms of code styling means that even a newbie to Go (which I was when we started writing Rex) can quickly start writing clean and readable code.
- Prior experience with Go. While much of Medium’s codebase is written in Node, we already had a few smaller-purpose microservices in Go. Adding another microservice in a language that we as a company have familiarity with makes building and maintaining this new service much easier.
We’ve talked a bit about the motivations for building Rex and what language we wanted to use. How does Rex actually work?
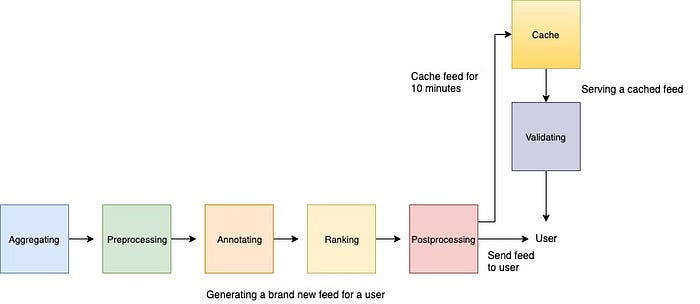
The generation of the Medium feed can be described in seven basic steps: aggregating, preprocessing, annotating, ranking, postprocessing, caching, and validating.
Aggregating
We source stories we think a user will enjoy, and we understand users may like stories for different reasons. For example, you may always read stories from authors or publications you follow. Or perhaps you really like technology and always want to read stories in the technology topic. For your feed, we have many different story providers, each of which provides you with stories we think you’ll like for a particular reason.

The three stories here were surfaced for the following reasons:
From your network: This story was published in a publication I follow (500ish). Rex sources the top-performing stories from publications I follow (like with topic-based providers, we look at stories in a publication many users have read and clapped on).Based on your reading history: Based on the stories I’ve read and clapped on so far, users with a reading history similar to mine have also liked this story. Finding users with a similar reading history to mine and making recommendations based on those is a technique called collaborative filtering, which Rex relies on to find high-quality stories for each user.Photography: I followed the photography topic, so for my homepage, Rex sources some of the top-performing stories in this topic (that is, the stories in the photography topic that many people have read and clapped on), and adds them into my feed.
Preprocessing
Once we’ve aggregated these high-quality stories for the user, we filter out stories we think may not be suitable for a user at a given time. Maybe we’ve sourced a user a story they’ve already read — there’s no need to show them the same story twice. We may add a preprocessor to remove stories the user has read before. During the preprocessing step, we use different preprocessors to filter out stories, with each preprocessor filtering for a particular reason.
Annotating
Once we’ve amassed a group of stories we think a user will like, we have to rank them by how much we think a user will like each story. Before we can rank them we have to fetch a significant amount of data from our data stores to get all of the necessary information (for example, who is the author of a story, what topic is the story in, how many people have clapped on this story, etc.). We calculate most of the features we need for ranking stories via offline Scala jobs and store them in two tables that we query at the time of feed creation. This allows us to minimize the number of I/O calls we’re making when assembling all the necessary data.
There’s information about each particular user ↔ story pair that can’t be calculated offline and has to be checked online (for example, does the user for whom we’re generating a feed follow the author of a particular story?), but precalculating the features lets us do much of the work beforehand.
Ranking
Once we’ve gathered all the necessary data to rank each story, actually ranking the stories depends on what ranking strategy we use. We first transform the results from the annotation step into an array of numerical values and pass each story and set of values to another Medium microservice that hosts our feed-ranking models. This separate microservice assigns a score to each story, where the score represents how likely we think the user is to read this particular story.
A lot of great work has gone into building Medium’s model-hosting microservice as well, but that’s a tale for an upcoming Medium Engineering story. 😉
Postprocessing
After ranking stories, there are often some “business rules” we may want to apply. Postprocessors apply story-ranking rules that ensure a better user experience. For example, we’ll see the top of a user’s feed dominated at times by a single author, single publication, or single topic. Because we want a user to see a more diverse set of authors, publications, and topics represented, we added a postprocessor that prevents a single entity from dominating the top of a user’s feed.
Caching
Once we’ve finished generating the feed, we store the feed in Redis, an in-memory data store, for future use. We don’t necessarily want to show a new feed every time the user visits Medium. This could make for a confusing user experience if they’re visiting Medium often in a short amount of time. Hence, after generating a feed, we store the feed in Redis for a short period of time.
Validating
If we’re reading our feed from the cache, some of the stories in the cached ranked-feed list may no longer be suitable for candidates. For example, if I follow and subsequently unfollow a given author, I should remove stories from that author from my feed if stories by that author are in my cached feed. The validation step filters out potentially unwanted stories from the cached feed, stories that may have been suitable candidates when we first created it.
When we first rolled out Rex, the benefits were immediately clear. Instead of ranking 150 stories, we can rank 10x that amount for a given user, and creating a new feed in Rex takes less than one second for 95% of requests.
🎉 🎉 🎉🎉 🎉 🎉🎉 🎉 🎉🎉 🎉 🎉🎉 🎉 🎉🎉 🎉 🎉🎉 🎉 🎉🎉 🎉 🎉🎉🎉
Just as great is how easily extensible this service is: Plugging in a new type of provider (for sourcing different story types) or testing out new business rules/preprocessing rules is a straightforward process and lets us easily test out new strategies to make recommendations at Medium the best they can be.
Rex is a continuously evolving service — the work described here laid the foundation for making recommendations at Medium better. Within Rex, we’ve experimented with new ranking models, new strategies for “cold-start” users, new tests related to our collaborative filtering algorithms, and much more. In addition, we’ve expanded Rex to power recommendations across more and more surfaces across Medium, and making sure that Rex has the ability to scale gracefully with the extra workload has posed an awesome challenge in and of itself.
There’s never a shortage of new and impactful recommendation and machine-learning challenges to tackle at Medium. If you’re interested in working on recommendations systems that affect millions of people each day, we’d love to talk with you.

